DCGAN Object Elimination Modeling
2020.08.21

1. Introduction
Dynamo Tech Solutions Co., Ltd. and LASTMILE WORKS Co., Ltd. have collaborated to develop an automatic image processing technology that eliminates objects in pictures and complements the object area with a background image. This kind of work needs professionals in the photo-editing field because it’s hard for computers to ensure the consistency of complemented images. Machine learning is one of the solutions to such systems, including ambiguity work.
DCGAN is a major image-generation method based on machine learning. It includes two models: 1) a “Generator” that generates a fake image similar to the real one and 2) a “Discriminator” that discriminates whether an input image is a “fake image” generated by the Generator or an unprocessed “real image.” In order to acquire a highly accurate Generator model, these two models are trained alternately.
In this project, we apply DCGAN to develop the system for object elimination in images. We show the method and the results of the study in this article.
2. Training
Our method refers to a DCGAN model that can evaluate the consistency of two regions, the complemented local region and the whole global region of the image).
An input of the Generator is a 128 x128 pixels RGB color image (hereinafter this is called “Input image”) with an additional grayscale image (hereinafter this is called “Mask layer”). The Mask layer defines the pixels that the Generator should complement. The Generator generates an image only in the white part of the Mask layer, so as to take into consideration that the generated image should match with the surrounding background. At the last step, the Generator merges the input image and generated image together. The generator model has two parts of a neural network: 1) an encoder part formed from a convolutional neural network (CNN) and 2) a decoder part formed from a transposed convolutional neural network (Transposed CNN) (Fig. 1.).
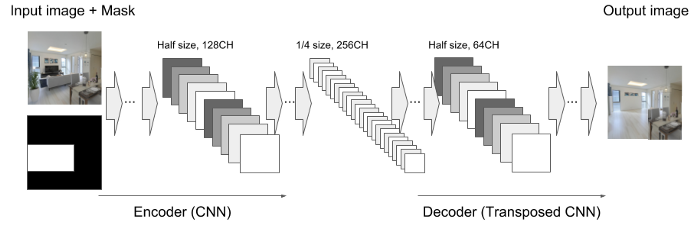
The inputs of the Discriminator are the entire image of 128 x 128 pixels, and the local region extracted at 64 x 64 pixels and centered on the complemented area by the Generator. The Discriminator judges whether the images are real or fake as a value from 0 to 1. The Discriminator model has two parts: 1) a CNN for Global and Local regions encoder, and 2) a fully connected neural network that combines the outputs of both global and local CNN (Fig. 2.).
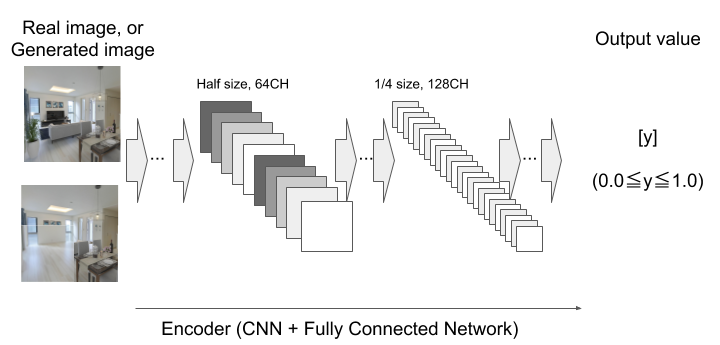
In addition, we adopt the following policies in order to stabilize the training process.
a. The Discriminator starts its training in the beginning. When the average of the Discriminator’s loss in the past ten (10) instances gets lower than a certain value — in other words, when the Discriminator can discriminate the fake image generated by the Generator with high probability — we switch the training target to the Generator.
b. When the average of the Discriminator’s loss exceeds a certain value — in other words, when the Discriminator cannot distinguish if the image is a real image — we switch the training target to the Discriminator.
During the process, the Discriminator can always discriminate false images with high accuracy. As the result, the Discriminator can lead the Generator to improve its quality too.
Our system uses Python 3 and TensorFlow to develop a machine-learning model, and further uses the Places2 dataset as training data. The training steps are as follows:
- Retrieve a raw image (Image A) from training data. Also, prepare an image that is painted a part of Image A with a gray color, put it into the Generator with Mask layer, and get a generated fake image (Image B).
- The Discriminator trains in order to recognize Image A as a real image, and Image B as a fake image.
- The Generator then trains to make the Discriminator recognize Image B as a real image.
- After many iterations of steps two (2) and three (3), we obtain a Generator that can complement any part of images with consistency.
Fig. 3 shows the results of an image complement by the Generator after training. Real images are on the left; images that are painted with gray at a random region are in the middle; images complemented by the Generator are on the right. The Generator complements the painted region with acceptable quality.

3. Object Elimination
The trained Generator can complement the painted region of images with consistency. It means that if we paint on images to cover an object and let the Generator complement the painted region, the object should not be in the output image of the Generator. As the result, it works as an object-elimination system.
We used TensorFlow Serving to deploy the trained model. TensorFlow Serving provides RESTful API to get the output of the trained model, so we can totally split the whole system into two parts, the server side that runs TensorFlow training code and the client side that uses the trained model.
The client is a simple paint application that works on browsers. The paint application sends the Ajax request to TensorFlow Serving with the image data to complement, and then shows the complemented image in the TensorFlow Serving response data. Fig. 4 is an example of the result.
4. Future Tasks
The goal of this project is to develop a system to eliminate objects such as furniture from interior pictures. Once we get those kinds of pictures, they are useful to propose different room coordination. Furthermore, we are planning to extend the target to 360-degree panoramic images to apply the technology in 3D.
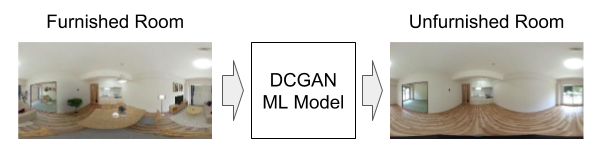
There are only a few public training datasets of panoramic images. Thus it is not easy to obtain highly accurate trained models. The solutions in such situations are technologies called “Transfer Learning” and “Fine Tuning,” so we are planning to apply them to our system as the next target.
5. References:
1) Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. “Globally and Locally Consistent Image Completion”. ACM Transaction on Graphics (Proc. of SIGGRAPH), 2017.
2) Places dataset: http://places2.csail.mit.edu/
3) TensorFlow Serving: https://www.tensorflow.org/serving

Vann Ponlork
AI Engineer
AI Engineer , Working at Dynamo Tech Solutions Co., Ltd. Currently, researching AI technology
