DCGANによる物体除去
2020.08.21

1. Introduction
Dynamo Tech Solutions Co., Ltd. とLASTMILE WORKS Co., Ltd. では、静止画中の物体を除去し、補修する技術を開発しています。補修箇所は画像全体に対して違和感のない形とするために、人間の手作業によってこの補修作業が実施されてきました。また、プログラムにより作業の自動化を試みる場合においても、定式化しにくい曖昧な判断基準を多く含んだ作業であるために、従来の手続き型プログラムでは実現が難しい分野と言われています。機械学習は、学習方法に工夫を施すことで上記のような曖昧さを含む問題に対する解決例が多く、関連分野で注目を集めています。
機械学習による画像補修手法のうち主要なものとして、DCGANが挙げられます。この手法は、本物に近い偽画像を生成するGeneratorモデルと、画像が「Generatorによって生成された偽画像」か「本物の画像」かを判別するDiscriminatorモデルという、相反する目的を持ったモデルを交互に学習させることで、高精度な画像生成モデルを獲得する技術です。本プロジェクトではDCGANを画像内の物体除去および補修に応用しており、ここではその手法と、検討結果の例をご紹介します。
2. Training
本検討では、補修した領域(local領域)と、画像全体(Global領域)の2つに対して、画像の自然さを評価できるDCGANの方式を参考としました。
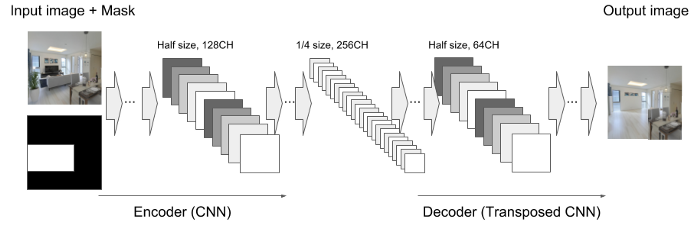
Generatorの入力は、128x128pixelの画像と、Generatorに画像を生成させる箇所を定義するためのMask層とを重ねたデータとしています(Fig. 1.)。Generatorは、Mask層の白色の部分に対してピクセル情報を除去したのち、周囲の背景とマッチするように画像を生成して、入力画像と生成画像を統合して出力します。Generatorモデルは、CNNより形成されるEncoder部分と、Transposed CNNより形成されるDecoder部分により形成されます。
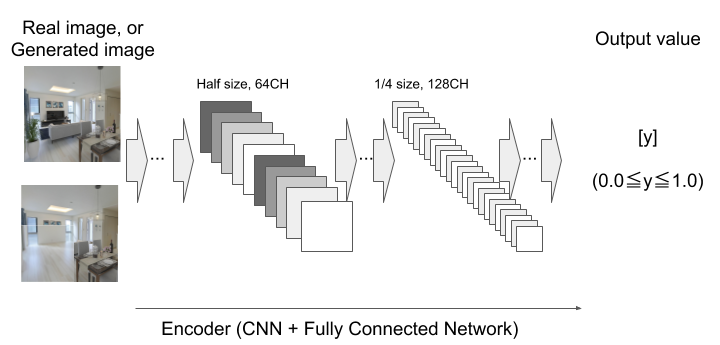
Discriminatorは、128x128pixelの画像全体のGlobal領域と、修復されたエリアを中心として64x64pixelのみ抜き出したLocal領域をそれぞれ入力とし、それらが本物の画像か、偽画像かを判定した結果を0から1の値で出力します。Discriminatorモデルは、GlobalおよびLocal領域それぞれに対応するCNNと、両CNNの出力を結合するFully Connected Networkにより形成されます(Fig. 2.)。
また、安定した学習を実現するために、学習の基本方針を下記の通りとしました。
a. はじめはDiscriminatorから学習を開始し、Discriminatorの過去10回のLoss平均値が一定値を下回った場合、つまりDiscriminatorがGeneratorの作成した偽画像を高確率で判別できる状態となった場合に、学習対象をGeneratorへと切り替える。
b. Generatorを学習させることにより、DiscriminatorのLoss平均値が一定値を上回った場合、つまりDiscriminatorがGeneratorの作成した偽画像を判別することができなくなった場合に、学習対象をDiscriminatorへと切り替える。
上記の方法に従うことで、Discriminatorは常に高い精度で偽画像を検出できるために、どのようにすれば本物に近い画像を生成することができるかをGeneratorに対して示すことができます。機械学習モデルの構築には、Python3とTensorFlowを利用しました。
本検討では、一般公開されている Places dataset を教師データとして使用しました。学習の流れは概略下記の通りとしています。
- 教師データの画像(Image A)のうち、ランダムな箇所を単色で塗りつぶし、Generatorに塗りつぶし箇所を補修させて偽画像(Image B)を作る
- Discriminatorに対して、Image Aを本物の画像、Image Bを偽物の画像として判別できるように学習させる
- DiscriminatorにImage Bを本物の画像として認識させるように、Generatorに対してImage Bの生成方法を学習させる
- 2. 3. の繰り返しにより、塗りつぶし箇所を本物の画像のように自然に補修できるGeneratorを得る
Fig. 3. に、学習後のGeneratorの画像補修の結果を示します。左から、本物の画像、ランダム箇所を塗りつぶした画像、塗りつぶし箇所をGeneratorにより修復した画像、としました。本物の画像を完全に再現することはできませんが、比較的自然な形で塗りつぶし箇所の補修がなされていることを確認できました。

3. Object Elimination
学習して得られたGeneratorは、画像の塗りつぶされた箇所を、あたかも本物の画像であるかのように自然に補修することができます。そのため、画像内のある物体領域を塗りつぶした状態でGeneratorに補修させると、Generatorはその物体がないものとして補修するため、結果として物体を除去した自然な画像が生成されると考えられます。この仕組を利用して、DCGANによる物体除去を試しました。
学習済みモデルを実利用するにあたって、ここではTensorFlow Servingを利用しています。TensorFlow Servingでは、TensorFlowの学習済みモデルによる動作をREST API形式で提供できるため、機械学習プログラムを動かすサーバ側のプログラムと、それを利用するクライアント側のプログラムとを疎結合にできるメリットがあります。
クライアント側のプログラムは、ブラウザ上で動作する簡易的なペイントアプリケーションとしています。ペイントアプリケーションで修復箇所を塗りつぶし、修復対象の画像を含めたリクエストをTensorFlow Servingに送ることで、修復画像を含むResponseが得られます。Fig. 4. にその一例をアニメーション形式で示しており、一定程度の精度での修復を確認することができます。
4. Future Tasks
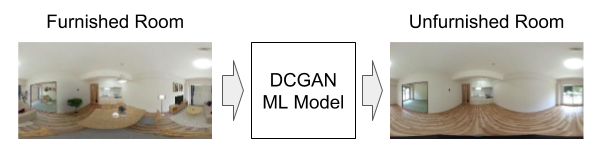
本プロジェクトのターゲットは、室内空間の画像から家具などの物体を除去する技術を構築することです。その結果、これまで取得に手間がかかっていた、入居済み物件に対する空室時の画像の自動生成が可能となります。さらには、この技術を360度のパノラマ画像に対して適用することで、3D空間へとその適用範囲を拡大していく予定です。
5. References:
1) Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa. “Globally and Locally Consistent Image Completion”. ACM Transaction on Graphics (Proc. of SIGGRAPH), 2017.
2) Places dataset: http://places2.csail.mit.edu/
3) TensorFlow Serving: https://www.tensorflow.org/serving

Vann Ponlork
私はAI/機械学習エンジニアです
機械学習の技術開発, ウェブアプリケーションの開発を担当しています
